YOLO v8n 踩的坑

准备魔改YOLO v8,实现一个基于YOLO v8的实时交通标识检测系统,这篇文章就是记录一下步骤。 那么问题来了,我甚至都没有做过视觉模型的项目,我该怎么做呢?
那么首先从YOLO v8开始,学习它的架构和实现。
准备工作
WSL 配置
Windows主力机就用的WSL2,可以直接按照 Microsoft的文档 安装WSL2。
使用添加程序和功能,找到Windows Subsystem for Linux,勾选它。
之后,这个:
1 | wsl --update |
后来发觉自带的命令行不太舒服,就安装了Windows Terminal。 这个选装,不影响使用,如果不想看直接跳到初始化Git仓库。
安装Windows Terminal
可以参考Microsoft的文档 安装Windows Terminal。 我直接使用GitHub的版本,下载页看这里: Windows Terminal GitHub页面
下载那个后缀为msix的文件,双击安装。安装完以后Win+R输入wt,就可以打开Windows
Terminal。
初始化Git仓库
初始化Git仓库,将ultralytics的仓库作为子模块复制到本地,正好帮我补充Git子模块的知识,小巧思这块儿。 (这一步是因为我的服务器没有GPU,没法使用opencv,只能使用opencv-headless代替, 之后在其他机器上的部署都是直接使用的pip内的ultralytics库)
注意,我在写这段的时候还没装GPU,但是之后我买了张P40 24G,之后我就不对CPU训练单独测试了。
1 | git submodule init |
pip安装ultralytics库之后,会有一个叫yolo的命令,这是ultralytics提供的一个命令行工具,用于训练和推理YOLO模型。
YOLO v8 复现
YOLO 识别复现

1 | from ultralytics import YOLO |

秒了。
YOLO 训练复现
1 | from ultralytics import YOLO |
有结果了,结果出在ultralytics/runs/detect/下,根据名字不同,每个文件夹对应一个训练任务。
就不指望这个训练结果能有什么了,上面这段只是用来验证一下能否训练的。
自定义数据集
感谢@Tianli发布的TT100K-YOLO数据集,原本的TT100K是无法直接用于YOLO训练的。Tianli这个集经过清洗,可以直接用于YOLO的训练。
当然,ultralytics自己也提供了一个数据YAML,也可以直接训练。(位置在ultralytics/cfg/datasets/TT100K.yaml)
我先是用的Tianli的数据集,然后再使用的ultralytics的YAML。
自定义数据集有点反应,但是效果比较差。试试看ultralytics的数据集。
一直被结果折磨。为啥效果还是差呢?


参数如下:
1 | yolo_coco.train(name='YOLOv8-COCO', epochs=300, data='./TT100K.yaml', |
DeepSeek给出了一份训练参数,如下:
1 | # Training Settings |
其中有这么一句话:
epochs: 300 # TT100K类别多(221类),需要更长训练;前两次300epoch仍未收敛
未收敛?加到700epochs试试。
秒了。附个结果以及两条曲线。
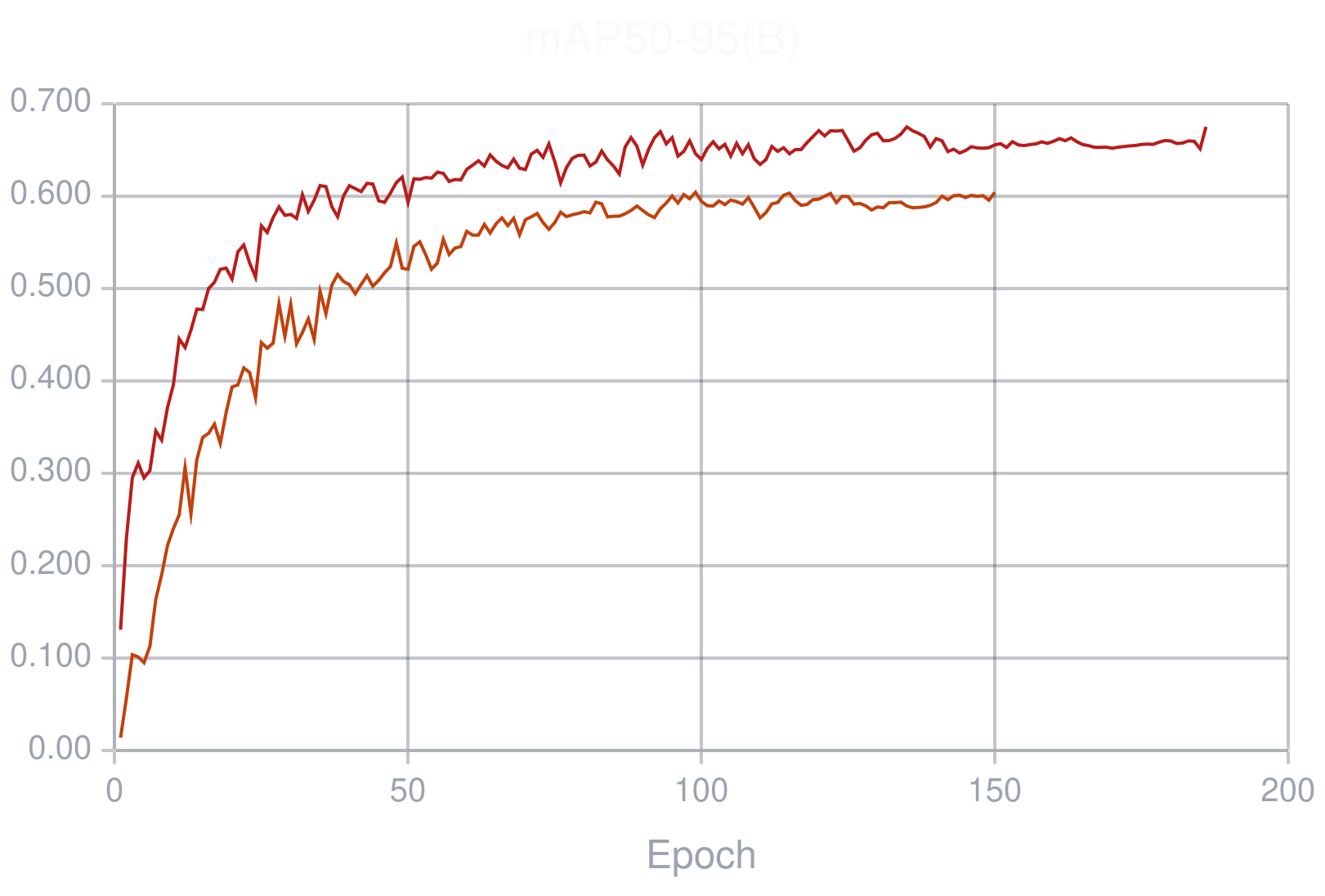
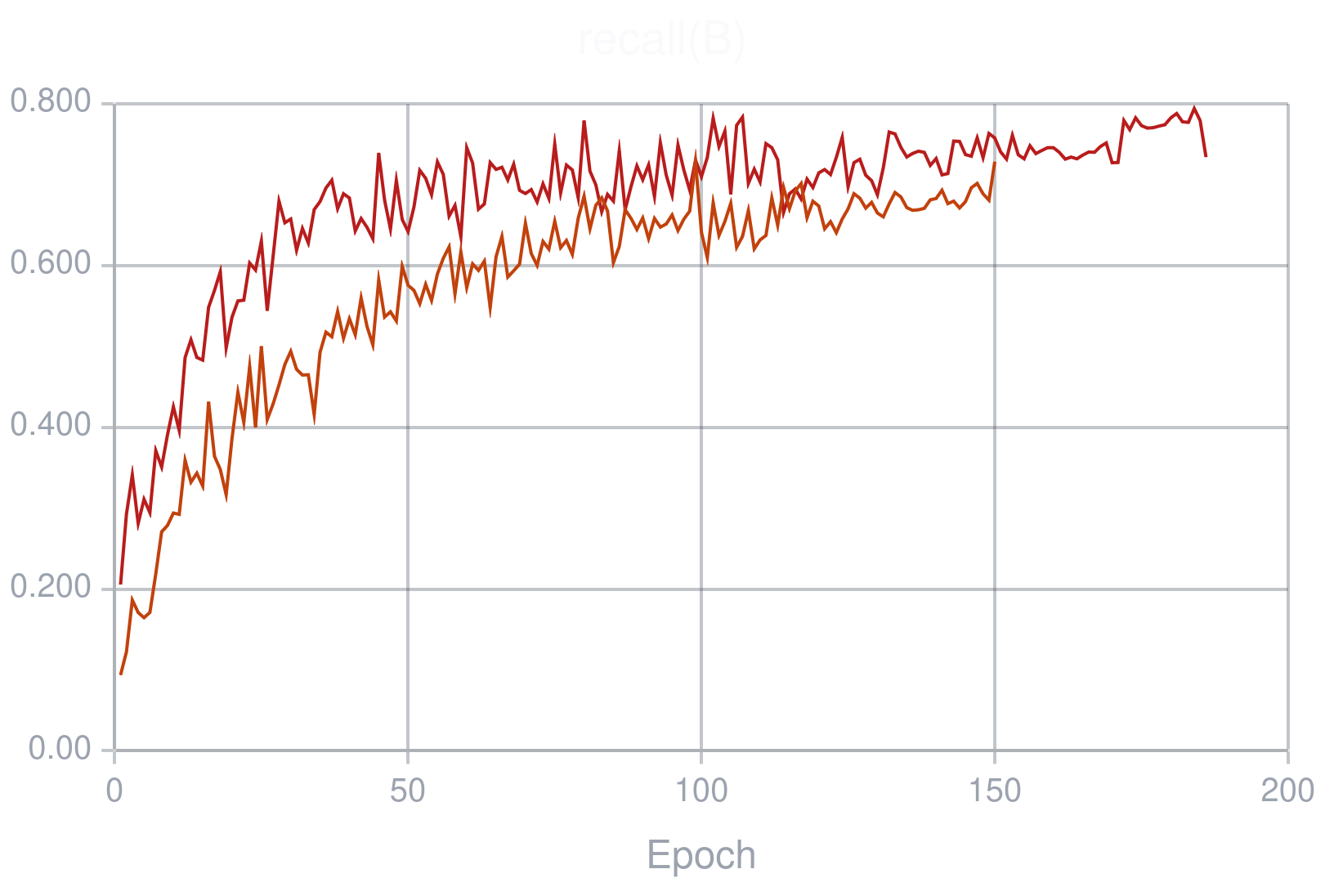
附上一个最终使用的YAML(最后使用的是Ultralytics的训练平台,这样可以训练快一些。):
1 | # Training Settings |
魔改YOLO v8
在此之前……
说起来,为什么AMP开启之后会自动下载YOLO26呢?这个问题一直没搞懂,从开始复现YOLOv8n的训练开始,一直到在官网训练好了YOLOv8n,它一直都需要下载YOLO26n的模型权重,这件事情困扰了我很久,直到现在。AI真好用。来自DeepSeek:
问题根因分析
你遇到的不是bug,而是 Ultralytics 最新版本中 AMP 功能检查的硬编码行为。
核心原因
在
ultralytics/utils/checks.py的check_amp()函数中(约第 765 行),AMP 验证硬编码使用了YOLO("yolo26n.pt")来进行混合精度功能检查:
2
3
4
5
6
7
8
# ...
try:
from ultralytics import YOLO
assert amp_allclose(YOLO("yolo26n.pt"), im) # ← 硬编码 yolo26n.pt
LOGGER.info(f"{prefix}checks passed ✅")
except ConnectionError:
LOGGER.warning(f"{prefix}checks skipped. Offline and unable to download YOLO26n for AMP checks. ...")为什么 amp=true 和 amp=false 行为不同?
在
ultralytics/engine/trainer.py的_setup_train()方法中:
2
3
if self.amp and RANK in {-1, 0}: # ← 仅当 amp=True 时才触发
self.amp = torch.tensor(check_amp(self.model), device=self.device)
amp: true→ 触发check_amp()→ 下载yolo26n.pt进行 AMP 功能验证amp: false→ 跳过check_amp()→ 不下载任何东西,直接训练这会改变你的模型吗?
不会。 下载的
yolo26n.pt仅用于验证 AMP 是否在你的 GPU 上正常工作,不会替换你指定的 YOLOv8 YAML 文件。你的实际训练模型仍然是 YOLOv8n。这个下载纯粹是功能检查的副作用。这是已知问题
GitHub 上已有 PR #23199(“Amp check yolo26”)试图将硬编码的模型名改为动态获取,但因代码缺陷(
NameError)被关闭。截至目前(2026年5月),该问题尚未修复。
确实嗷,看这里:
1 | try: |
哪个小b……聪明写的这玩意儿? 气死我了。问题解决,AMP启动,下载就下载吧,你只要别把训练目标自动切换为YOLO26n就可以了。
魔改:CBAM注意力
所以,为什么是注意力机制?YOLOv8本身的结构是一种卷积神经网络的变体,它的原有结构没有设计为为微型目标专门设计优化。 众所不周知,卷积是对所有的特征进行统一提取,没有针对性的提取不同目标的特征。 所以需要引入注意力机制,来提取不同目标的特征。
注意力有很多,比如SE-Net、CBAM、ECA-Net等。这里就取CBAM。
CBAM在YOLO仓库里有一个声明,但是好像有点小问题。那借助DSv4Pro重写一下:
1 | """ |
目前的YOLO结构文件变成:
1 | # Parameters |
那么问题来了:为什么不只在最后添加CBAM模块?CBAM需要逐层对特征图进行处理,才能实现全局特征的增强。 如果只有一层CBAM,效果不强,起不到太多作用。
魔改:Wise-IoU
Wise-IoU相较于YOLO的CIoU有什么优点呢?上公式。
这是普通的IoU:
这是CIoU:
1 | cious = iou - (u + alpha * ar) |
其中:
这是WIoU:
1 | pb = pred_bboxes[fg_mask] # [N_fg, 4] |
WIoU相对于CIoU,对于高质量的预测框和过低质量的预测框,对最后框影响降低;对于普通质量的预测框就相对提高。
魔改:P2小目标层
对于YOLOv8而言,已经有了大中小三个检测层:
1 | # Backbone不变 |
这里,[15, 18, 21]三层的结果作为22层输入,分别是P3,P4,P5层的特征。我们在原YOLOv8的YAML结构加入P2层之后,变成这样:
1 | # Backbone不变 |
这里[18, 21, 24, 27]四层就是P2到P5的特征,进入检测头。P2比原来的再深入一层卷积。
这是网络结构的叠加,还算直观。
最终修改
1 | # P2 + CBAM |
拜托DS写个猴子补丁:
1 | """ |
最终结果就是这样了。开始训练。
结果
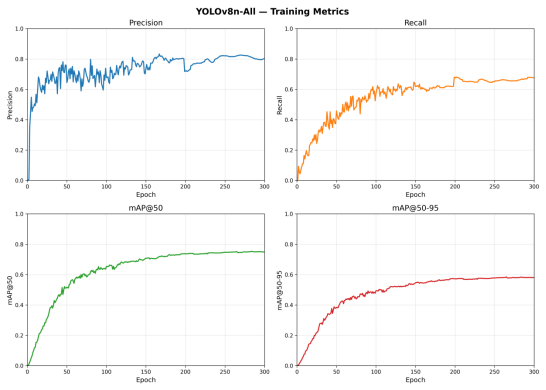
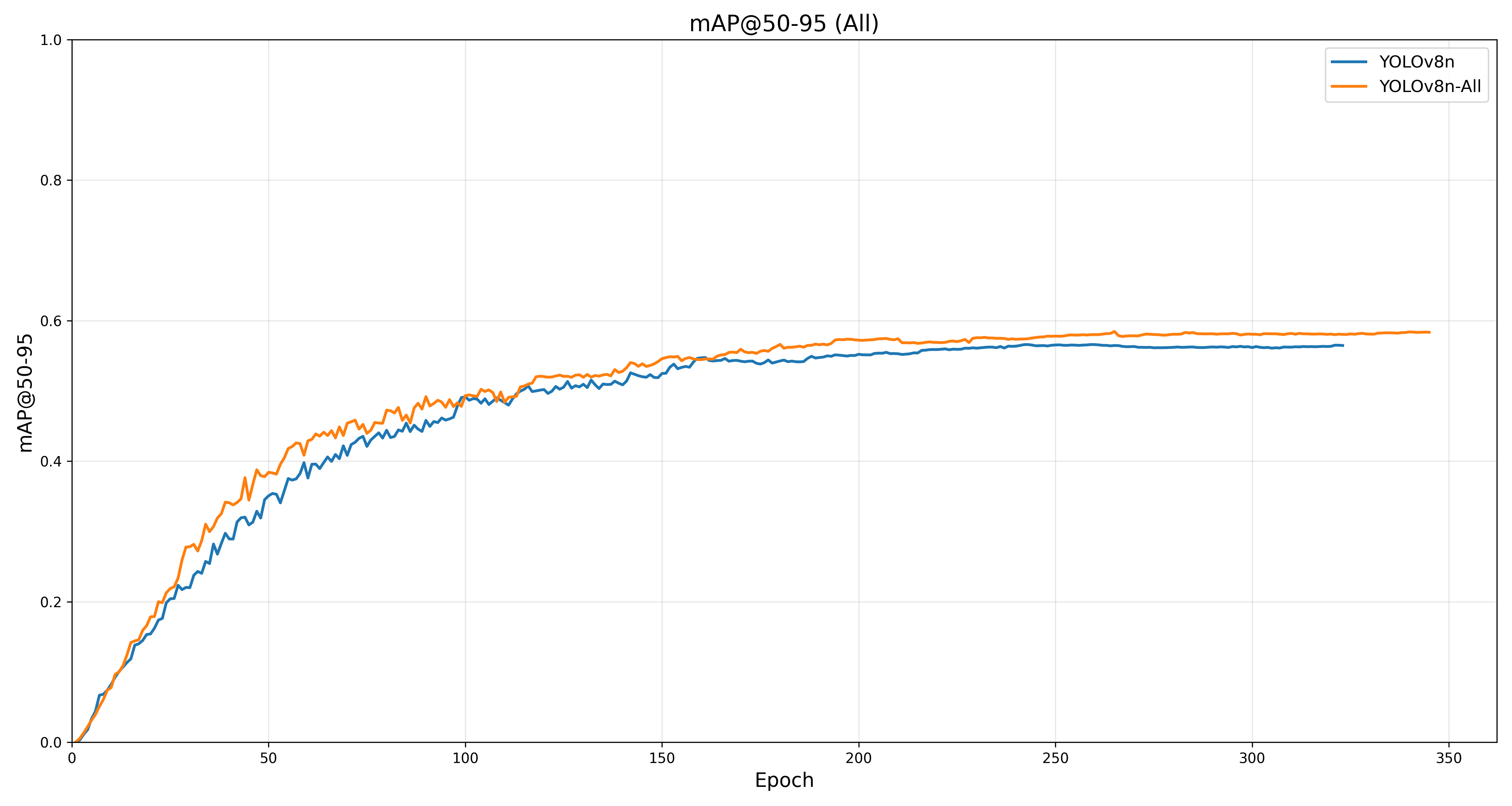
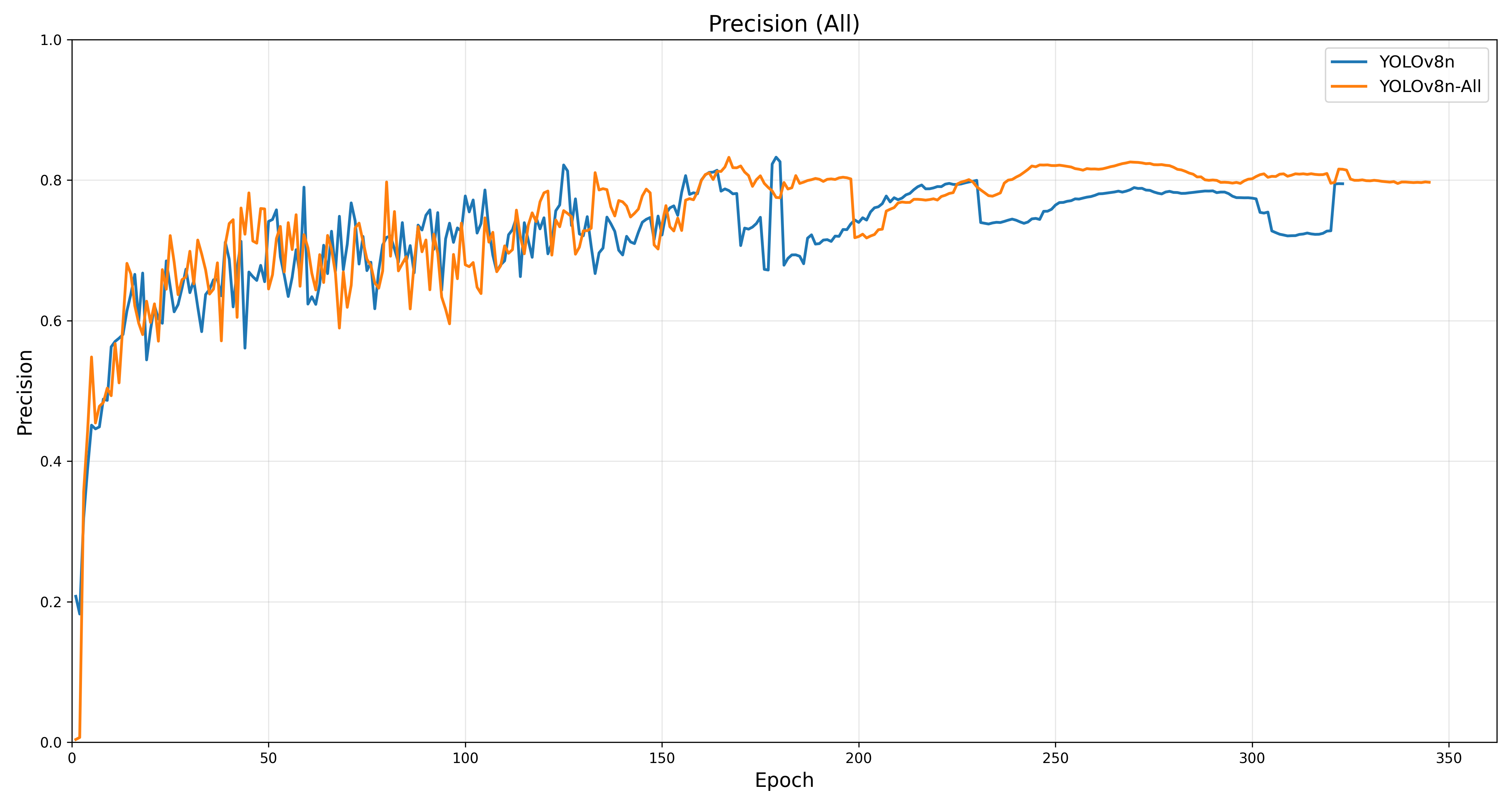
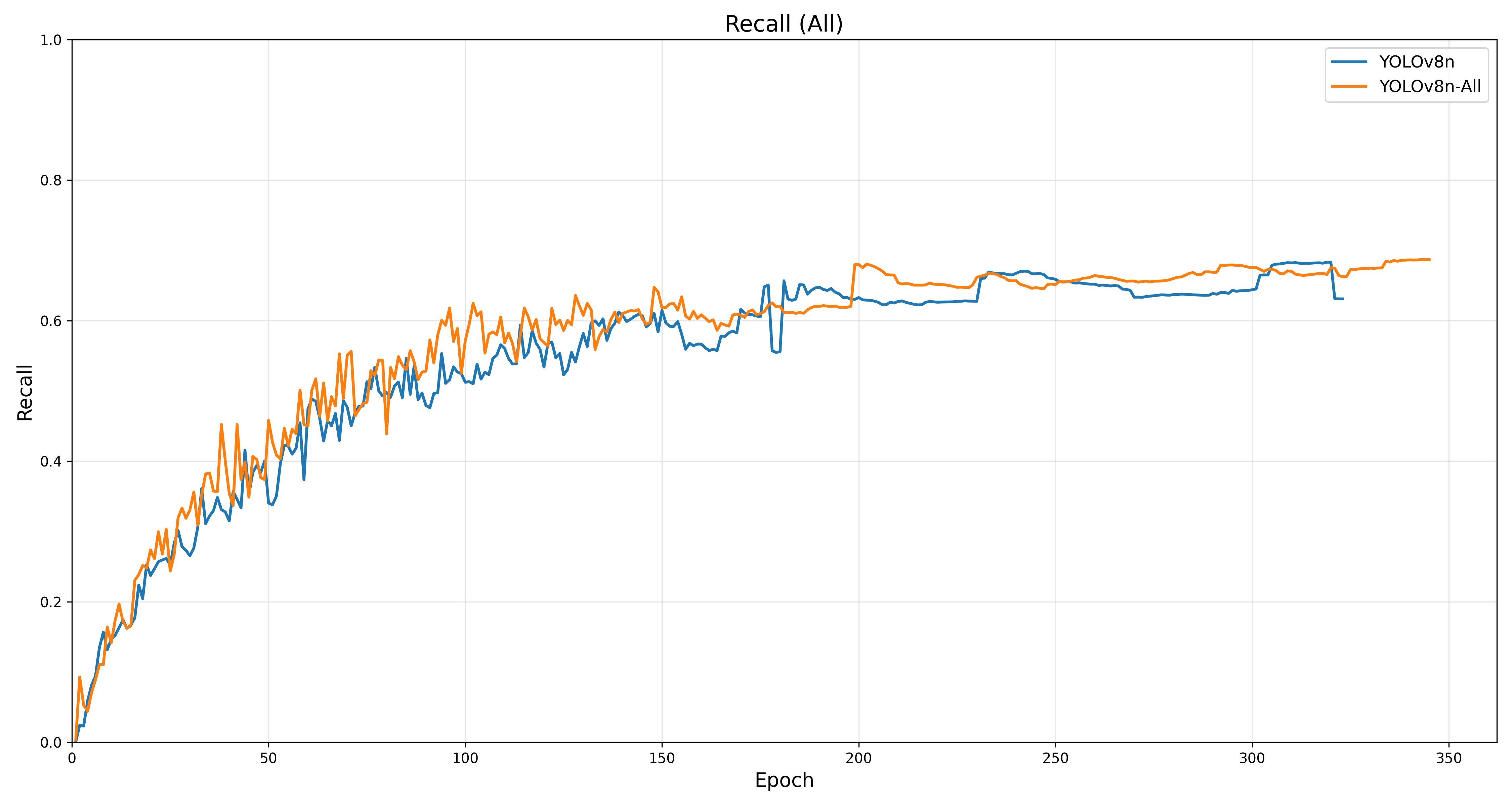
唉……至少高了一点吧,mAP50-95最后到0.5几了,倒也不是不行。
- 标题: YOLO v8n 踩的坑
- 作者: 容小狸
- 创建于 : 2026-05-06 07:30:14
- 更新于 : 2026-05-23 16:16:58
- 链接: https://blog.rongxiaoli.top/2026/05/05/YOLO-v8/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。